
The Implementation Journey: Document Processing
Need to catch up? Start with Part 1.
Implementing LAD-RAG on real SOC 2 reports revealed that the paper’s elegant ideas needed significant hardening for production use. Memory exploded. Edges proliferated. LLMs degenerated into repetitive loops. Graph density collapsed community detection. Each problem required innovation: edit-based memory updates, topic graduation, deterministic linking strategies, multi-layered degeneration prevention, and density-aware pruning.
This is the story of building LAD-RAG++, a stabilized and improved implementation that actually works on 300+ page compliance documents.
Phase 1: Building the Paper
I tried implementing the paper, as described, first. Page-by-page extraction, running memory accumulating entities and topics, edges connecting nodes across the document. The first page worked, but quickly had some scalability problems.
Page 1 of a simple 6-page policy document produced 40 tracked entities for just 14 extracted nodes. That’s 2.86 entities per node. The paper talks about tracking “key high-level information” and “active entities under discussion,” maybe 10–15 meaningful entities per page. Instead, my implementation was tracking example names (“John Smith”), metadata values (“November 23, 2020”), common nouns (“employees”), and even character counts (“14 characters”). Everything that looked vaguely important got added to the memory.
The token economics were brutal. Each page required thousands of output tokens just for the memory structure. Project that to a 100-page compliance document and you’re looking at at leasts tens of thousands tokens just for working memory, before you even get to edges or the actual content. And I was seeing JSON truncation failures. The LLM was producing malformed output because the response was simply too large. It wasn’t feasible to keep upping the max tokens cap on the LLM output; every additional token raises the chance of hallucination.
This obviously didn’t scale. Having the LLM regenerate the entire memory structure on every page was far too many tokens. I needed to rethink prompt processing. I created a new version of the experiment where the memory prompt and the edges prompt were separated, every page produced debug output and I could carefully consider how they were working across each page.
Phase 2: Discovering the Right Architecture
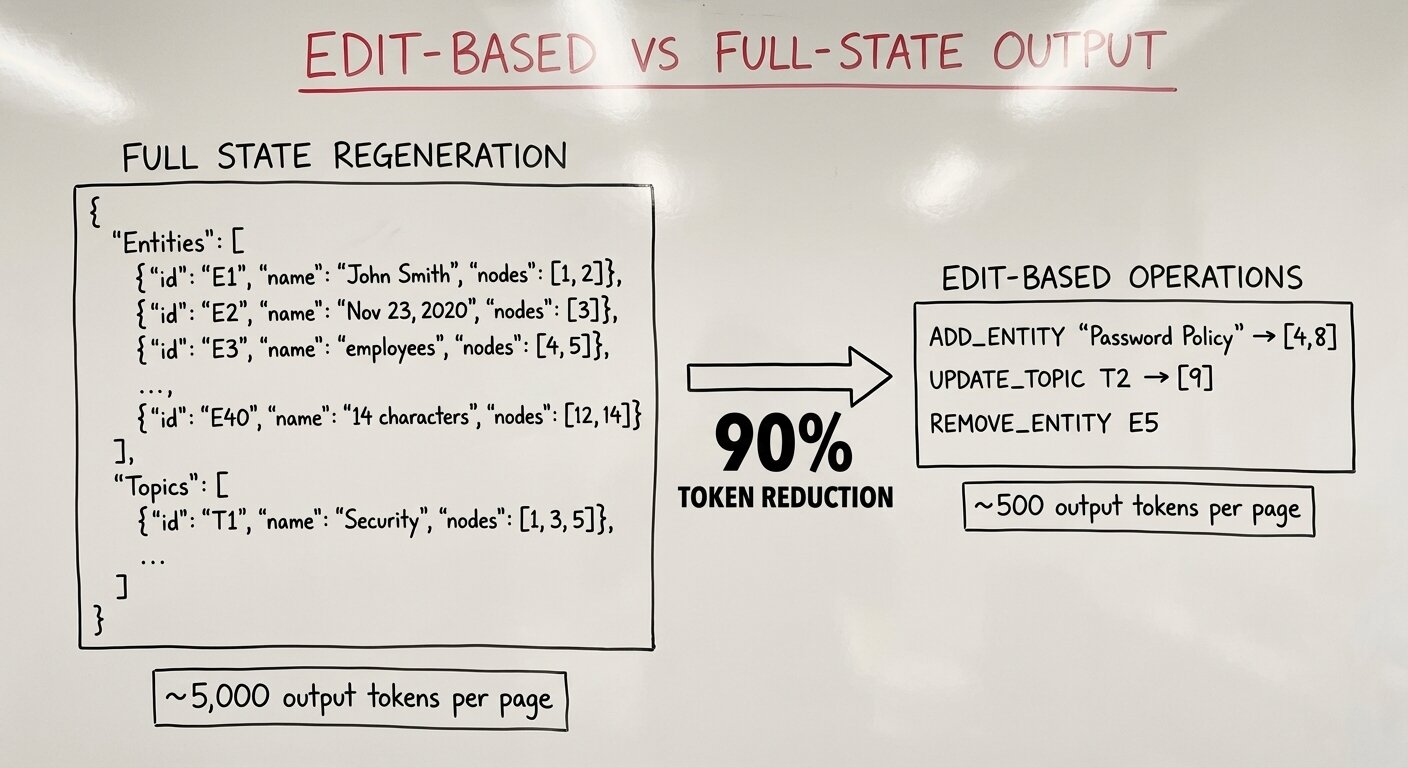
Studying the prompts more closely, I tried a different approach: what if the memory and graph structures were tracked by deterministic code and the LLM only outputs changes to those structures, not their full state?
Instead of regenerating all entities on every page, what if the model just said ADD_ENTITY "Password Policy" → [4], [8]? The state management happens in deterministic code; the LLM’s job is just to identify what’s semantically relevant. This “edit-based” approach cut output tokens by roughly 90%. Suddenly a 100-page document started to seem feasible.
As I kept studying the prompt processing, I realized the structural connections defined by the section hierarchy (IS_PART_OF_SECTION) didn’t require LLM judgment at all. The LLM was already telling me when sections started and ended through a “section queue” mechanism. I could derive all the IS_PART_OF_SECTION edges deterministically from that queue using zero tokens. The LLM’s job narrowed further: only create edges that require semantic understanding (CONTINUES, REFERENCES, EXPLAINS, UPDATES).
Next came the “index-replace” optimization. The paper’s approach references nodes by verbose object IDs like page_0002_obj_013. This seems like a simple thing, but it was a critical insight from the authors. Assigning globally unique object IDs are what enable cross-page edges. Without them, you can’t reference a node from page 3 when you’re processing page 15. However, when a prompt has a multitude of nodes in it, suddenly you are consuming a lot of input tokens through all these verbose object_ids. Moreover, the LLM has to output lots of tokens to reference them which increases your cost and exposure to hallucinations.
I fell back on the “index-replace” optimization I’ve used often throughout my career: for any given prompt in this document processing pipeline, all the LLM needs is a set of unique indexes, these could be simple ints. I modified node extraction so when it completed (with its set of uniquely identifying object_ids), deterministic code also added, essentially, an ascending “primary key” that was just a simple int.
This let deterministic code map these ints to object_ids while the LLM only ever needed to see the ints. The result was a big token savings in both the user prompt and structured output schema. With a set of uniquely identifying ints, those ints can be passed at runtime into the json schema that defines the LLMs structured output (as enum members) dramatically saving tokens there and constraining output.
Constraining the LLM to select from a valid enum of indices reduces the chance of hallucination significantly; the model is far less likely to reference nodes that don’t exist.
Phase 3: Edge Explosion
When I was summarizing LAD-RAG’s approach above, I noted that the model connects new elements to running memory, creating cross-page edges. This is another useful insight from the authors: because of context window constraints you can’t simply pass all previous nodes into the window and ask the LLM to connect current nodes to previous nodes.
Instead, you present the running or working memory to the LLM and ask it to connect current page nodes to working memory items (entities, topics, unresolved objects). Because these are already connected to previous page nodes, you can take these LLM-created, nodes-to-working-memory-connections and deterministically connect current page nodes to previous page nodes. In other words, you connect current page nodes to previous page nodes through shared extracted entities, topics and unresolved objects.
This is a great insight by the authors, except problems emerged as we processed more and more pages. Topics were accumulating dozens of nodes, and each node in a topic created edges to every other mention of that topic. A single broad topic like “Password Policy” with 30 nodes could generate hundreds of edges, most of them noise.
My first attempt at combatting this was adding “subject domains” to the prompt. Every topic had to fit underneath a “subject domain”. My hope was that the LLM would take these extremely general topics (like “Password Policy”) and instead call them subject domains and create more targeted topics under the subject domain. This helped, but did not fix the problem.
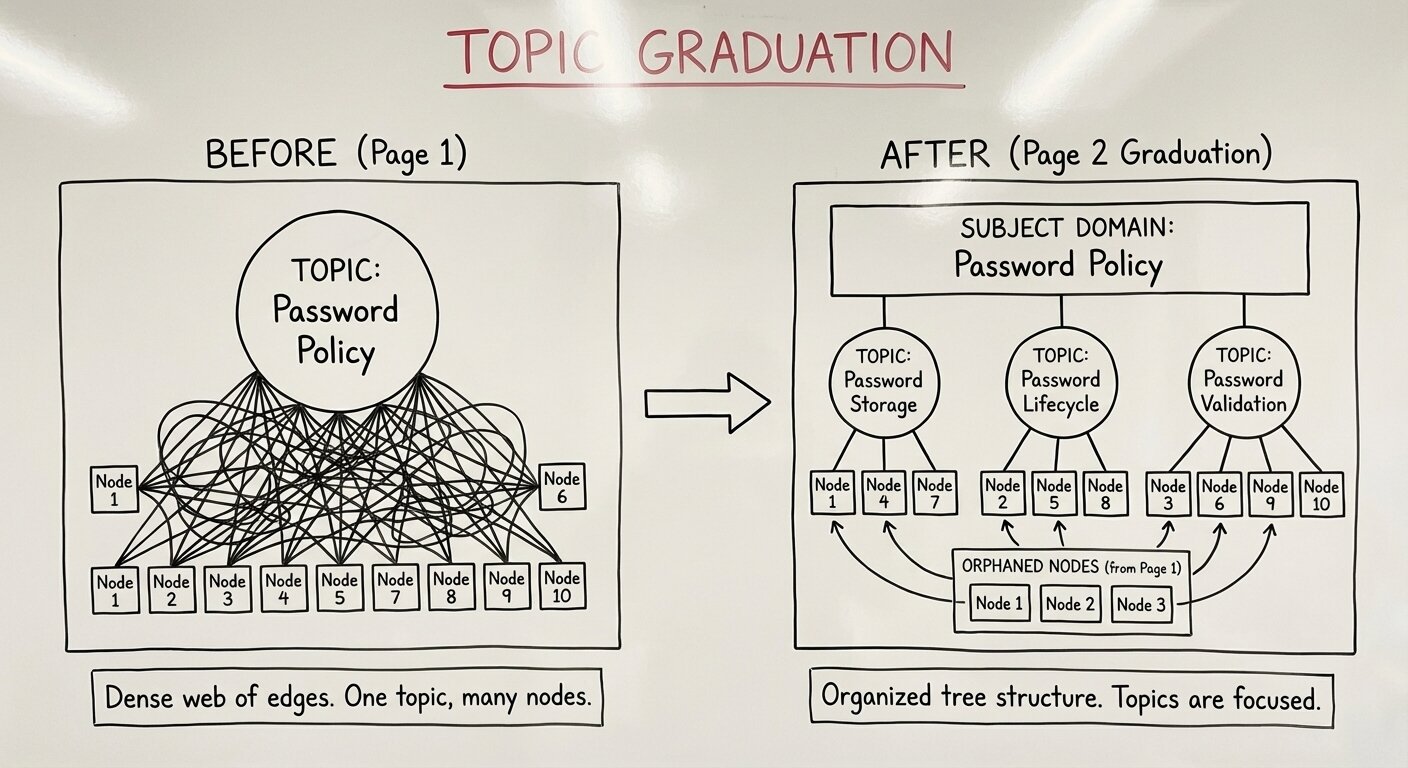
Think about it from the LLM’s perspective: on page 1 the last paragraph might introduce something whose topic is clearly “Password Policy”. On page 2, many more paragraphs might dive deeply into “Password Policy” (in my test case it was a bulleted list with like 20 bullets) which means “Password Policy” should’ve been a subject domain. But on page 1, the LLM has no idea what is coming and that Password Policy should be a subject domain. As such, I introduced “topic graduation.”
On page 2, where “Password Policy” is explained in much greater detail, the LLM now has the chance to graduate “Password Policy” into a subject domain and define more targeted topics underneath that new domain. These targeted topics will then have fewer nodes linked to them reducing the chance of edge explosion. This worked very well, but there was another wrinkle to it: what happens to the nodes already linked to “Password Policy” from page 1?
When a topic is graduated to a subject domain, we essentially “orphan” the nodes originally linked to it. Since we don’t know this graduation is going to happen in advance, we can’t have those previous page nodes ready and waiting in the memory prompt to be re-assigned to the new topics. The solution: dynamically add the orphaned nodes to the next prompt (the next page edges prompt) and instruct the LLM to re-assign the orphaned nodes before it creates edges. The potential for a lot of context here made me uneasy, but this strategy worked well, orphaned nodes consistently got reassigned to sensible subtopics.
“Password Policy” graduates to a domain containing “Password Storage”, “Password Lifecycle”, “Password Validation” as distinct topics. Now when page 50 discusses password storage, it creates edges to just the storage-related nodes, not every password-policy-related node in the document.
But this still didn’t fully solve the edge explosion problem. It was still possible, even for topics-under-domains to accumulate lots of nodes. Furthermore, when the LLM connected a current-page node to a working memory item like topic T2 “Password Storage”, it had to also select which previous-page nodes to link to. The problem: the LLM couldn’t see those previous page nodes. It was guessing which of T2’s nodes (say, [16, 17, 18, 19, 20]) were the right targets. This led the LLM to link to all of them and it continued to cause edge explosion.
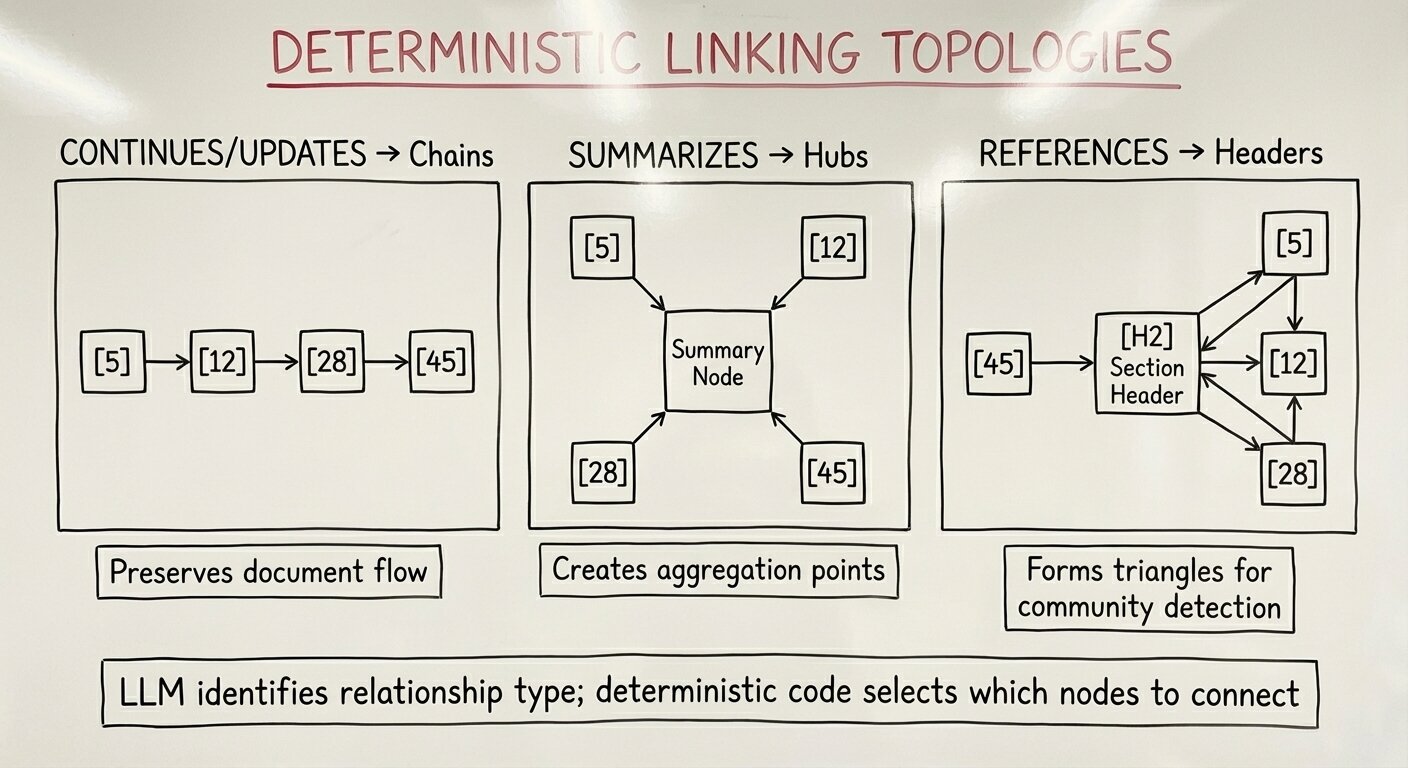
Here’s what worked: another separation of concerns. I realized the LLM’s job should be purely semantic: identify that a relationship exists and which memory item justifies it. There was no point in having the LLM tell us which previous nodes the current node linked to as it couldn’t see them anyway. It should be the job of deterministic code to select the actual targets based on the semantic relationship the LLM identified:
CONTINUES/UPDATES/EXPLAINS: Link to the last node in the topic (creates chains)SUMMARIZES: Link to all nodes in the topic (creates hubs)REFERENCES: Link to header nodes if the topic has them, otherwise all nodes
This “deterministic linking” strategy meant the LLM only needed to output from_index, relationship_type, and via_memory. No more target arrays to hallucinate. The schema shrank, saving ~1,000 tokens per page. More importantly, the graph topology became predictable: chains where content flows forward, hubs where summaries aggregate, and narrow references through section headers when available.
So far we’ve only discussed edge explosion relative to topics. Entities can suffer the same issue. An important entity could be global: it might appear on pages 1, 50, 100, and 200. If I applied the same REFERENCES strategy to entities (link to all nodes or headers), an entity appearing 50 times would create a “God Node” with hundreds of edges, warping any community detection algorithm. What worked: entities always use the last-node strategy, creating chains instead of hubs. This keeps entity edges from dominating the graph structure.
Why does this topology matter? At inference time, we use Louvain community detection to find clusters of related content. Chains preserve document flow while keeping communities tight. Hubs (for SUMMARIZES) create natural aggregation points. And when REFERENCES edges point to section headers, they form triangles with the structural IS_PART_OF_SECTION edges, the strongest structure for community detection.
Phase 4: Bounded Working Memory
Edge explosion wasn’t the only scaling problem. Even with topic graduation and deterministic linking, the working memory itself was growing unbounded. Every entity and topic extracted on every page stayed in memory forever. On a 100s-of-pages document, the memory display in each prompt could balloon to tens of thousands of tokens just for memory context, before any actual processing.
The idea was simple: recent items are more likely to be relevant than old items. An entity mentioned on page 5 that hasn’t appeared since page 10 probably isn’t relevant when you’re processing page 50. But it might become relevant again on page 200 if the document circles back to that topic.
Here’s what I built: a two-phase memory management system with dormant storage. Phase 1 applies Time-To-Live (TTL)-based eviction: entities that haven’t been touched in 5 pages move from ACTIVE to DORMANT state; topics get a longer TTL of 8 pages since thematic discussions span longer stretches (these page lengths are configurable). Unresolved objects (forward references like “see Table 3”) never evict, they must persist until resolved. Phase 2 applies Last Recently Used (LRU) enforcement: if the active memory still exceeds 50 items after TTL eviction, the oldest items by last-accessed-page get evicted until we’re under the threshold.
The important part: dormant versus deleted. Dormant items are hidden from prompts but preserved in storage. When the LLM re-extracts a dormant entity because the document mentions it again on a later page, the system reactivates that entity, merging the object IDs from both the original and new extraction. This enables cross-page connections even when dozens of intermediate pages didn’t mention the entity. The memory “remembers” across gaps.
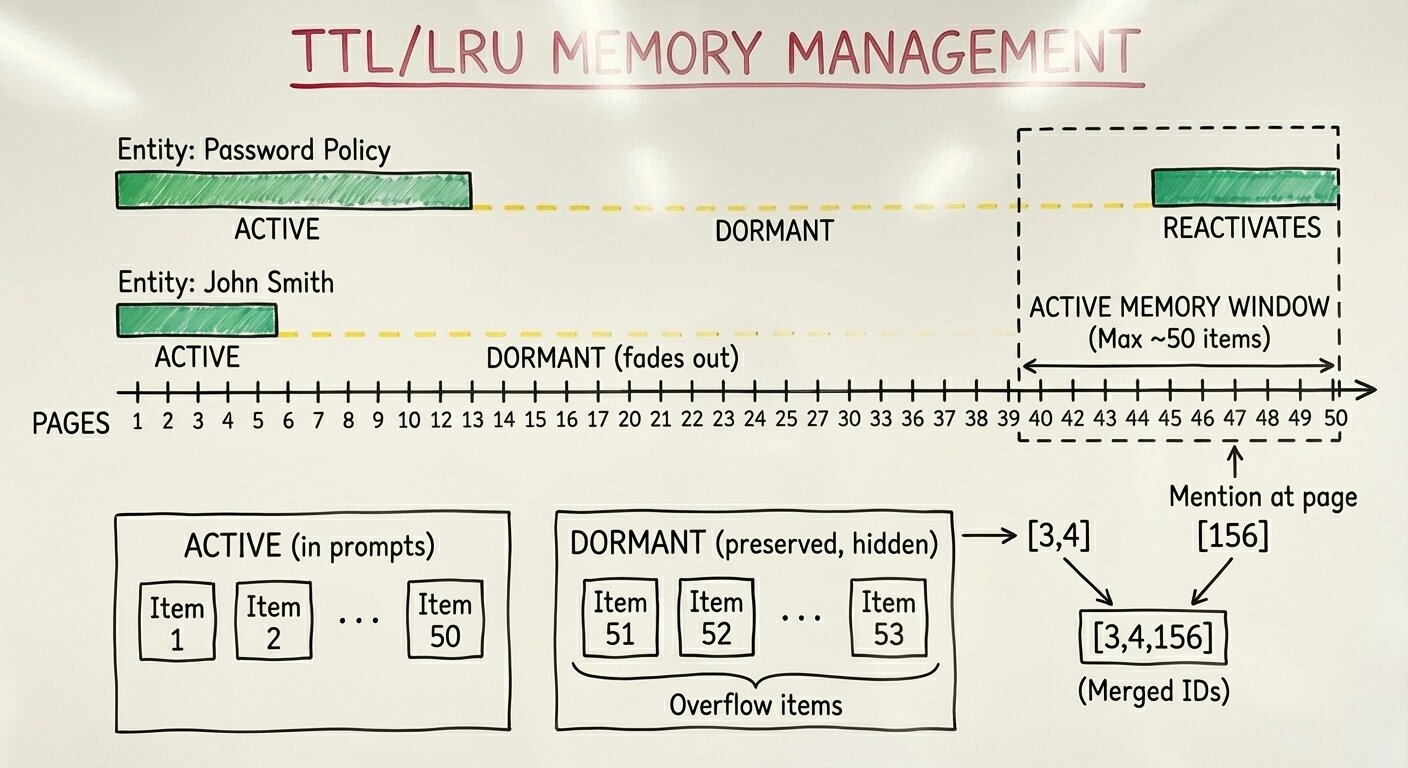
This achieved 75–80% reduction in memory display tokens. More importantly, it established processing independence: page 88 processes identically to page 8. The same bounded working memory, the same prompt structure, the same output expectations. Without this, processing time and cost would grow dramatically with document length. With TTL/LRU, they remain constant per page.
Phase 5: The SOC2 Test
Up to now, I had built all of this functionality using a 6 page Asset Management Policy in preparation for running a much longer, denser SOC2.
The test document was an 88-page SOC2 Type 2 compliance report. 580 nodes after extraction. Dense tables. Regulatory language. Many cross-page references. Everything that makes compliance documents hard.
I YOLO’d the first run through the system. Page 15 broke the system in a familiar way: the generated output hit max output tokens. This almost always meant the LLM had gotten stuck in a generation loop where it generated the same token(s) over and over until it hit max output tokens. This page contained dense tabular content where many entities linked back to many previous entities. The model would output the same relationship statement hundreds of times until it hit the max token limit and the JSON became unparseable. The model wasn’t hallucinating per se, it was stuck in a generation loop.
First change: frame the output as a SET, not a log. The LLM was treating its output like a stream of consciousness, “I see entity E1, write it. I see E1 again, write it again.” Adding explicit language that “each relationship appears EXACTLY ONCE” and that the output should be treated as a set of unique operations, not a chronological log of the reading process, helped significantly. It reduced the likelihood that the same relationship could be repeated, which was one of the core degeneration patterns.
But another degeneration pattern emerged. In the memory prompt, the LLM was issuing separate operations for the same entity across multiple nodes when editing working memory items: ADD_LINK E1 [59], then ADD_LINK E1 [60], then ADD_LINK E1 [61]. Each operation was technically unique, so SET framing didn’t catch it. The fix was batch indices: ADD_LINK E1 [59, 60, 61] as a single operation. One entity, one operation, all applicable nodes batched together. This greatly reduced output tokens and kept repetitive generation loops from starting.
A subtler issue appeared next. In the edges prompt, my structured output schema forced the LLM to state which memory item justified a cross-page semantic relationship via a single via_memory_index field. On page 15, a dense table node legitimately referenced multiple entities, E3, E4, and E5, all with the same REFERENCES relationship. The LLM had to output three separate relationship objects, one for each entity. This repetitive structure increased the likelihood of the generation loop. The fix was allowing the LLM to cite many memory items in one write: via_memory_indices: ["E3", "E4", "E5"] instead of three separate operations. As long as the semantic relationship type was identical, they could be batched. This kept the LLM from having to repeat the same node + relationship over and over to different memory indexes.
However, now that we introduced these arrays into the LLMs output, the degeneration could happen within the array itself. Instead of writing the same memory update or edge into the output until max_output_tokens, what the LLM would do is just repeat the same 3ish indices in the arrays until max_output_tokens.
As I thought about this issue, it occurred to me that while we know the LLM must select one index if it’s going to write an edit, minItems: 1, we also know, before the prompt runs, the maximum possible items it could add to the array: each one exactly once. So we can pass a maxItems to each structured output array, filled at runtime, with the length of the total items it could select (e.g. number of nodes, number of memory items). This provides signal to the LLM about what the maximum size the array can theoretically get to which further reduces the likelihood of infinite, repetitive generation.
The fifth fix was more philosophical. I’d gotten into a loop where I’d let Claude Code make a lot of edits to prompts as we worked through issues, then at certain points, I’d ask it to review the prompts from the LAD-RAG paper and make sure we were remaining “faithful” to the paper which would often prune information. This was slowly drifting the prompts away from the structure I’d preferred throughout my career:
- Thoroughly describe the task in detail.
- Place any runtime context into the prompt wrapped in xml tags.
- Place any questions at the end of this.
- The final context is a set of tags with numbered items containing explicit steps the LLM should take, each instruction should be a concise restatement of the detailed instructions in step 1.
This structure gives the LLM the chance to understand the task in detail before it reads runtime context. It can then process that runtime information through the lens of the detailed task instructions. After processing that large amount of information, it gets these concise pointers back to the detailed instructions right at the end, just before it starts generating. Returning to this structure also helped stabilize the output.
Each constraint alone wasn’t sufficient. Once all five fixes were made and working together (along with all the edge explosion fixes described above), processing the SOC2 stabilized. I had set up document processing so if at any point a LLM json output was broken or an index was hallucinated etc, the system would raise an error (i.e. it didn’t swallow or handle classic-LLM issues). I remember watching the first SOC2 complete end-to-end through document processing without errors. A lot of work had gone into stabilizing this process, and seeing it run clean on a full SOC2 document felt like real progress.
The Implementation Journey: Inference
With document processing stable, I turned to inference: how do you actually answer questions over these graph-structured documents? The LAD-RAG paper describes three retrieval tools exposed to an LLM agent, but the details of making them work well on long, dense documents required innovation.
Graph Quality
Why Louvain Community Detection
The LAD-RAG paper uses Louvain community detection to “surface coherent clusters of contextually related nodes.” Louvain is a greedy optimization algorithm that partitions a graph into communities by maximizing modularity, a measure of how densely connected nodes are within communities compared to between them. It’s fast, deterministic (with a fixed random seed), and works on weighted graphs.
For document retrieval, this matters. When you find one relevant paragraph, you often want related content: the section it belongs to, the table it references, the continuation on the next page. These related nodes cluster together in well-formed communities because the edges we created during document processing, IS_PART_OF_SECTION, CONTINUES, REFERENCES etc, encode exactly those relationships. A question about “password requirements” might surface one paragraph through semantic search; Louvain communities let us expand to the entire Password Policy section without retrieving unrelated content about audit logging.
The paper’s Contextualize tool leverages this: given a node, expand to its community members plus direct graph neighbors. This captures both “higher-order relationships” (nodes clustered by topic even without direct edges) and “local neighborhoods” (directly connected nodes).
But this only works if the communities are meaningful. A meaningful community groups semantically related content, nodes from the same section, discussing the same topic, or forming a coherent narrative thread. When you expand from a center node, you should get focused context: the surrounding paragraphs, the table being referenced, the definition being applied. Ideally, communities are large enough to provide useful context (5–20 nodes) but small enough to stay focused. A 580-node document would hopefully have 10s of communities, each capturing a distinct chunk of related content.
Dense graphs break this entirely. Louvain works by finding partitions where connections within communities are dense and connections between communities are sparse; that contrast is what modularity measures. When the graph is uniformly connected, there’s no contrast to optimize. The algorithm can’t find natural fault lines. It either collapses everything into a few giant communities or makes arbitrary cuts that don’t reflect semantic relationships.
The practical impact on Contextualize is severe. If Louvain produces 8 communities for 580 nodes, each community averages 72 nodes. Expanding to community members now floods the agent’s context window with noise instead of signal. Worse, genuinely related content might land in different communities while unrelated content clusters together, the exact opposite of what we need. That’s where the density challenges emerged.

Taming Dense Graphs
Remember that SOC2 document? Even after all the edge explosion fixes during document processing, the graph was still too densely connected: 2,935 edges across 580 nodes, but Louvain community detection only found 8 communities. Investigation revealed that REFERENCES edges comprised 62% of all edges, and a fallback in my deterministic linking code was the culprit. When a topic had no section headers to link to, the code fell back to linking to all nodes in that topic. One reference could create 30 edges. SOC2 reports are particularly prone to this pattern: they’re dominated by dense control language and test result tables, but fairly sparse section headers. A broad topic like “Security Risk Management” might accumulate 10s of nodes across a SOC2, and any reference to that topic would fan out to all of them.
The first line of defense was prevention during document processing itself. I added multi-layered density controls to the deterministic linking logic:
- Global topic detection: Topics with more than 30 nodes or spanning more than 40 pages are marked as “global.” The REFERENCES relationship is skipped entirely for these ubiquitous topics since they’d create edges to everything. A topic like “SOC 2 Compliance” appearing on 60 pages isn’t useful as a linking mechanism.
- Bounded fallback: When no section headers exist and the page window is empty, fall back to the last 3 nodes in the topic rather than all nodes.
These prevention measures reduced edge creation at the source. But it was certainly still possible to create a densely connected graph. I needed a second approach: detect density problems after community detection, then prune if necessary.
Detection runs after Louvain community building and evaluates multiple metrics: edges per node (critical if >8), REFERENCES percentage (critical if >50%), largest community size as percentage of total nodes (critical if >30%), communities per 100 nodes (critical if <2), and maximum/P95 node degree on prunable edge types. Each metric has healthy, warning, and critical thresholds. The worst status wins. Only CRITICAL status triggers pruning, and the detected issues get logged for debugging. For the SOC2 document, multiple metrics flagged CRITICAL: 62% REFERENCES edges, only 1.38 communities per 100 nodes, and hub nodes with 50+ connections.
When detection flags CRITICAL, two-phase pruning kicks in. Phase 1 is deterministic and requires no embeddings, it uses graph topology and edge metadata alone. Phase 2, which only triggers if phase 1 doesn’t reduce density enough, uses semantic similarity to filter edges. The result: meaningful Louvain communities that actually group related content instead of one giant blob.
Phase 1 starts by separating edges into two categories. “Core” edges: IS_PART_OF_SECTION, and CONTINUES define the document’s hierarchical and narrative structure; these are never pruned. “Prunable” edges: REFERENCES, EXPLAINS, SUMMARIZES, UPDATES represent the semantic connections that can proliferate during document processing.
For each node, we compute a core degree (how many structural edges it already participates in) and derive a budget: max(0, DEGREE_TARGET — core_degree). A node already anchored by five structural edges gets less budget for semantic edges than an orphan node. This prevents important structural hubs from becoming semantic hubs too.
Prunable edges get scored using a simple formula: type_weight × 0.95^page_distance. Edge type weights reflect semantic importance (UPDATES and EXPLAINS score higher than REFERENCES since they represent stronger content relationships). The recency decay (0.95 per page of distance) prefers edges between nearby content, a reference to something three pages back scores higher than a reference spanning fifty pages. Same-page edges naturally score highest.
We sort all prunable edges by this score, with deterministic tie-breakers (object IDs) ensuring identical input always produces identical output. Then we greedily select edges: for each edge in score order, we keep it only if both endpoints still have budget remaining. When we keep an edge, both endpoints’ budgets decrement. Without this “both-endpoint” constraint, hub nodes still accumulate connections, a popular node could exhaust its budget on incoming edges while still accepting outgoing edges through other nodes’ budgets. After phase 1 completes, we rebuild the graph and re-run detection. If the status drops to WARNING or HEALTHY, we’re done. But if the graph remains CRITICAL, perhaps because the edge type weights or page distances cluster similarly, phase 2 provides a second filter.
Phase 2 requires what phase 1 avoided: embeddings. For each remaining prunable edge, we compute the cosine similarity between the source and target node embeddings. Edges below a threshold (0.3) are dropped. The intuition: if two nodes aren’t semantically similar, an edge between them is likely noise. A REFERENCES edge connecting “Password Policy Overview” to “Audit Logging Procedures” through a shared topic might survive phase 1 on scoring, but phase 2 would catch the semantic mismatch. After phase 2, we rebuild and re-run detection one final time. In all the documents I processed, I never had to run phase 2.
Search and Retrieval
Question Generation
During indexing, I added question generation using the semantic topics extracted during document processing. An LLM generates questions that each document can definitively answer based on the topics we’ve extracted. These become “suggested questions” shown to users, questions we know the document addresses because they’re derived directly from its semantic structure.
The implementation batches topics by their subject domains to stay within parallel prompt limits. Each batch gets sent to the LLM, which generates an appropriate number of questions per topic based on complexity. A simple policy topic might warrant one question; a complex multi-faceted topic might generate three or four. The questions link back to their source topics, enabling the UI to group suggestions by theme.
I spent relatively little time on this feature; I think a lot more could be done here. Suggested questions should guide users toward productive queries. Auto-complete should surface questions we know the system can answer well. We already have a rich semantic structure from document processing, question generation is a cheap way to expose that structure to users.
Hybrid Search at Indexing Time
The LAD-RAG paper mentions “neural-symbolic indexing” but doesn’t detail how lexical and semantic search combine. I built a hybrid search system that runs at indexing time, creating both a custom BM25 index and dense embeddings from node summaries. At query time, these combine with configurable weights: fact-based questions (names, dates, specific terms) benefit from higher BM25 weight, while meaning-based questions benefit from higher semantic weight. The agent can adjust these weights based on what it’s looking for.
I wanted to make this “triple-hybrid” search and include sparse neural embeddings as well (e.g. SPLADE), but didn’t have time to implement this part. This would be a nice future addition.
Pre-Agentic Retrieval
The paper’s inference loop starts with the agent making its first tool call. But I realized many well-written questions could be answered from a single good search. Running hybrid_search(question) before the first LLM call and including those results in the initial prompt saves a round-trip in a bulk of queries. The agent sees the initial results, evaluates them, and can immediately signal “done” if they’re sufficient. Only complex questions requiring multiple searches, graph traversal, or contextualization need the full agentic loop.
ColBERT Reranking
Hybrid search retrieves candidates, but ordering matters. I integrated a ColBERT reranker (GTE-ModernBERT) as a second stage. Hybrid search retrieves 50 candidates, then the reranker reorders them by fine-grained token-level similarity, returning the top 10.
The reranker’s raw MaxSim scores are query-length dependent (longer queries produce higher raw scores), so I implemented affine normalization: score the query against itself (upper bound) and against an empty string (lower bound), then scale the raw score into that range. A score of 1.0 means “as similar as the query is to itself.” This makes scores comparable across queries of different lengths and much easier for human/LLM interpretation.
Query Reformulation
Initial hybrid search uses the user’s exact question, but users phrase questions differently than documents. “Password requirements” in the question might be “credential policies” in the document. I added explicit query reformulation as part of the agent’s instructions. The agent can issue multiple reformulated queries in a single tool call, each targeting different phrasings. Results are kept separate per query (since rerank scores are query-dependent), with nodes appearing in multiple queries flagged as “duplicates,” a strong relevance signal.
Agent Tools
Safe Graph Queries
The LAD-RAG paper’s second tool, SymbolicGraphQuery, enables structured queries over the document graph: “find all tables,” “get everything in section 4,” “show nodes on pages 10–15.”
For this, I built a JSON DSL with five operators: eq (exact match), contains (substring), in (match any in list), and, and or. The LLM generates a filter specification like {"field": "type", "op": "eq", "value": "table"} or nested combinations like {"op": "and", "filters": [{"field": "page", "op": "in", "value": [1,2,3]}, {"field": "type", "op": "eq", "value": "paragraph"}]}. Deterministic code executes these filters safely.
A silly bug derailed this approach at first. Gemini’s structured output would always produce {} for the filter field, an empty object, no matter what examples I provided. The problem: I’d defined filter as a bare OBJECT type with no properties. Gemini had no schema to follow, so it defaulted to empty. Instead of greatly increasing the size of the structured output schema, I instead changed filter from OBJECT to STRING. The LLM now outputs filters as JSON strings, which I parse server-side. This enabled recursive AND/OR combinations and polymorphic values (strings, ints, lists) that a rigid object schema couldn’t express.
For displaying graph query results, I created an “inventory view”, results grouped by page in reading order rather than a flat list. When the agent asks “show me all tables,” seeing them organized by page provides spatial context that a score-ordered list loses. This is distinct from orbit/constellation views (which have center nodes); graph query results are peer nodes filtered by attributes.
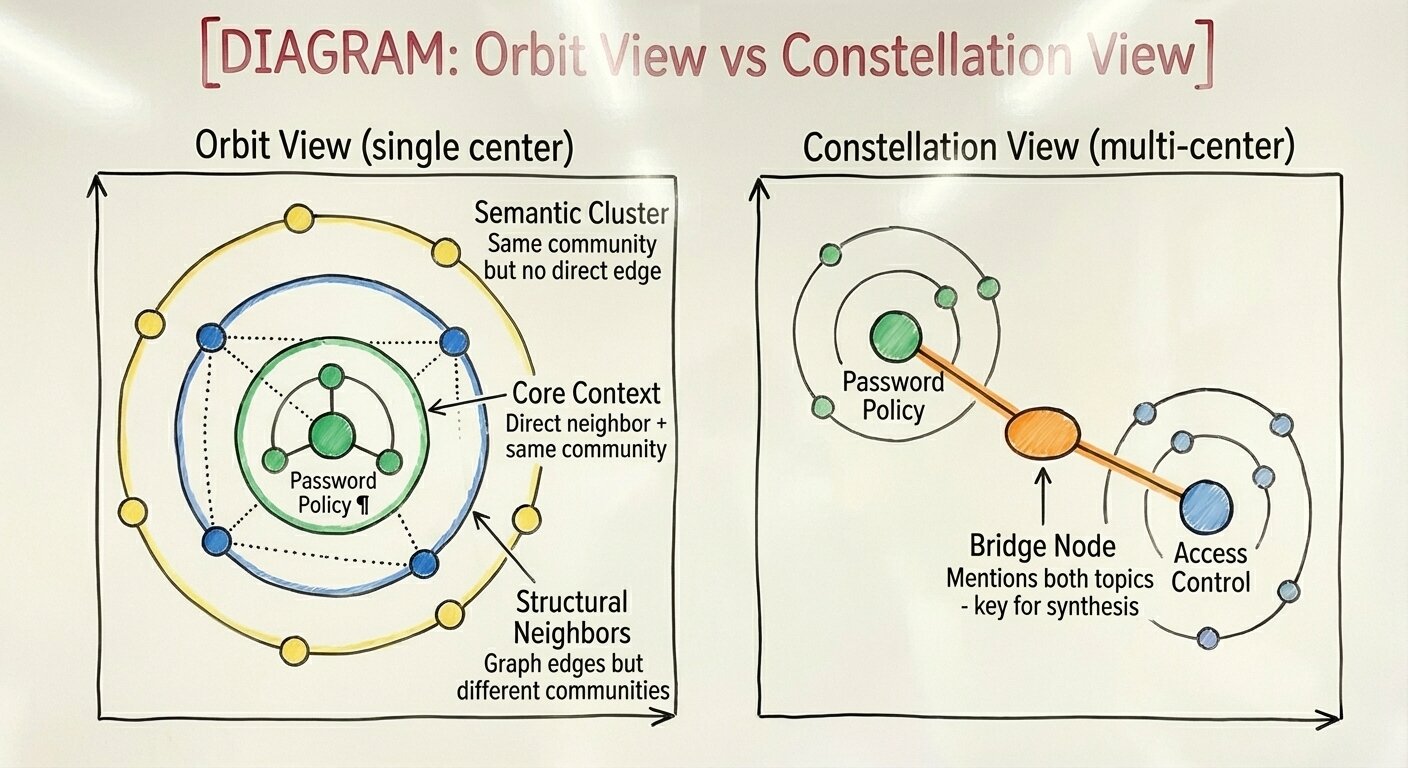
Orbit and Constellation Views
The LAD-RAG paper’s Contextualize tool expands a node to its community and neighbors. But presenting results as a flat list loses the topology information that makes the graph valuable. I introduced “orbit view” for single-node contextualization: the center node at the core, then nodes grouped by relationship strength. “Core context” nodes are both direct neighbors AND in the same Louvain community, the strongest signal. “Structural neighbors” have graph edges but different communities. “Semantic cluster” nodes share a community but no direct edge.
For multi-node contextualization (exploring 2–3 nodes together), I created a “constellation view.” This identifies bridge nodes, nodes connected to multiple centers, which are often the key for synthesis. If you’re exploring “Password Policy” and “Access Control” together, a bridge node mentioning both topics is extremely valuable.
Taming Contextualize Explosion
The orbit and constellation views made topology visible, but a deeper problem emerged: contextualize was returning far too many nodes, especially when queried with multiple centers. Selecting 5 center nodes expanded to 217 context nodes, an entire section of the document flooding the agent’s context window. We needed some way to intelligently prune contextualize results as well.
Two root causes drove the explosion. First, community expansion was unbounded. When a center node belonged to a large Louvain community, every member came along for the ride. Second, bridge attribution was too generous. Any node sharing a community with multiple centers got flagged as a “bridge,” even if it had no direct graph connection to any center. A node in a 40-member community touching two centers would appear as a bridge when it was really just community noise.
The fix combined a hard cap with intelligent ranking. MAX_CONTEXT_OUTPUT = 50 nodes regardless of how many the algorithm wants to return, this ensures we never explode the LLM context window. If we miss a critical node, the agent can always issue another contextualize call with different inputs.
But a hard cap alone isn’t enough; we need to try and keep the right 50 nodes. The ranking algorithm uses a two-pass approach to guarantee centers are never dropped. Pass one adds all center nodes unconditionally, even if MAX_CONTEXT_OUTPUT is less than the number of centers, we keep them all. Pass two fills the remaining budget from non-center candidates.
For non-centers, a sort key determines priority: (-bridge_score, type_rank, global_index, node_id). Bridge score counts how many center nodes this candidate connects to via actual graph edges, nodes connecting multiple centers float to the top. Type rank classifies nodes into three tiers: preferred types (paragraph, table, figure) rank highest as they carry the most semantic content; neutral types (section_header, title, footnote) come next; excluded types (header_footer, metadata) are filtered out entirely since they add bulk without semantic value. The global index preserves document order for nodes that tie on other criteria. The node ID provides a final deterministic tiebreaker; the same input always produces identical output.
The bridge attribution fix was the subtle insight. Previously, node_to_centers was populated from both graph edges and community membership. A node in the same community as two centers would appear connected to both, even with no direct edges. Now only actual graph edges count. Community membership makes a node a candidate for inclusion, but with bridge_score=0 it won’t displace genuinely connected nodes. The result: ~40 false bridges dropped to a handful of genuine structural connections.
Relevant Evidence Marking
A subtle but important change: instead of passing all retrieved nodes to the QA generator, I added explicit relevance marking. After each retrieval step, the agent marks which nodes are actually relevant to the question. This is additive since once marked, a node stays relevant. Only marked nodes flow to the final answer generation, filtering out noise from broad searches.
This also enabled meaningful “unanswerable” responses. When the agent exhausts its search strategies and marks no evidence as relevant, the QA generator receives empty evidence plus the agent’s final reasoning about what it searched for. It can then explain why the question can’t be answered from this document, rather than hallucinating or giving a generic “not found.”
Index-Replace Everywhere
The index-replace optimization from document processing proved equally valuable in inference. Instead of verbose [page_0002_obj_013] references, all prompts use compact [13] indices. The agent, reranker, and QA generator all work with these indices, with deterministic code mapping back to object IDs when needed. Beyond token savings, constraining the LLM to select from a valid enum of indices (only those present in current evidence) meant index hallucinations were far less likely.
Richer Evidence Presentation
Beyond retrieval, the graph structure lets you show why evidence connects, not just what was retrieved. Vanilla RAG dumps retrieved chunks in a ranked list. LAD-RAG’s graph reveals the connections between them.
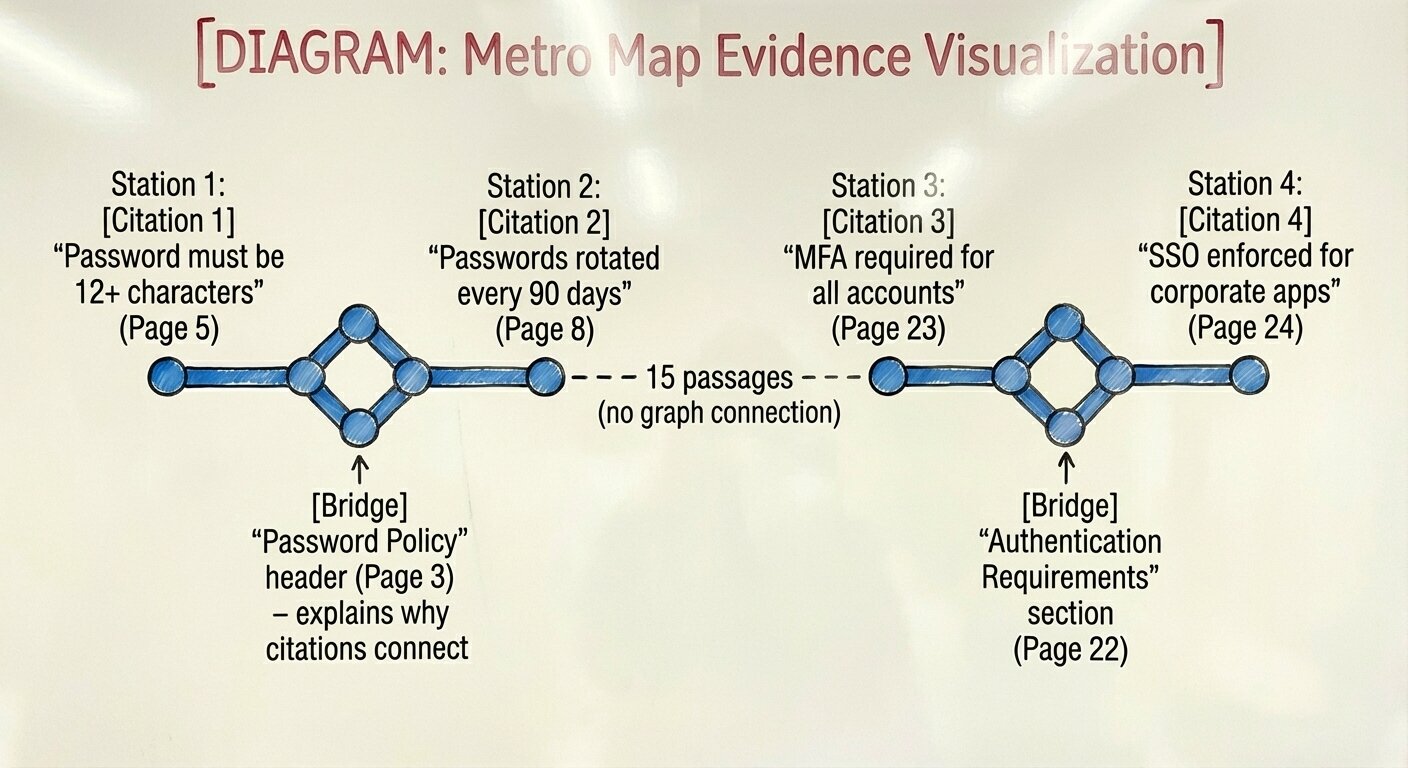
Bridge nodes surface the shared context linking citations. If citations [1] and [3] both connect to a node defining “the Password Policy,” that bridge node explains why these two passages belong together. The user sees not just what was retrieved, but the semantic thread connecting them.
Topic grouping organizes evidence by Louvain community. Instead of a flat list, citations cluster by theme, all the authentication-related evidence together, all the access control evidence together. The labels derive from section headers (no LLM calls needed).
Reading context shows the ±N surrounding passages for any citation. Because nodes preserve document structure, you can present evidence in true reading order with the preceding and following content intact.
I designed a “Metro Map” visualization concept: evidence displayed in reading order with bridge nodes inserted inline between connected citations. Gaps show “N passages between” when citations aren’t graph-connected. The result is a linear narrative showing how the answer’s supporting evidence flows through the document, something ranked chunk lists can’t show.
The Compound Effect
These pieces work independently, but together they compound. Pre-search seeds the agent with good candidates. Query reformulation catches terminology mismatches. Reranking surfaces the best matches. Orbit/constellation views make topology visible. Relevance marking filters noise.
I built a streamlit frontend to query this system and observe the agentic retrieval. It was fun watching it handle multi-hop questions, reformulate queries, handle graph-query questions that previous RAG systems I’d built could’ve never handled. Perhaps one of my favorite uses was watching retrieval for
"Explain the org's secure coding practices."
In this particular SOC2, the answer to this question was spread out throughout multiple parts of the document. Vanilla RAG would’ve returned maybe one or two of them (and our pre-search results did). Our agent would recognize those nodes and pass them to contextualize() to ensure it got the full picture. This tool call was critical to find all the disparate pieces of evidence that answered this question. The tool would correctly return the communities around secure coding practices and pass a fully qualified set of evidence to the QA system to produce a complete answer.
Evals
This long blog post has had a gaping hole in it since the beginning: evals. AI engineers reading this are breaking their keyboards wondering why I made them read all of this without clear evals in place. And they’re right, the proper way to go about this experiment would have been to spend a lot of time up front creating careful evals for document processing, inference etc.
Despite not having a strong eval, I believe some real contributions were made. Processing stability served as a proxy metric, SOC2s completing without degeneration, JSON parse failures, or index hallucination was itself a signal that the constraints were working. Graph metrics provided structural validation: community count improving from 8 to 20+, REFERENCES edge percentage dropping from 62% to under 30%, hub nodes shrinking from 50+ connections to reasonable degrees. And manual spot-checking of generated answers against source documents caught obvious failures early. These aren’t formal evals, but they’re not nothing either.
Formal evals for this domain are genuinely hard. Human annotation is expensive, and reasonable annotators might disagree on whether two paragraphs share a CONTINUES vs REFERENCES relationship. Community quality metrics exist (modularity scores, silhouette coefficients), but they measure graph properties, not semantic usefulness for retrieval. Multi-hop retrieval evaluation requires human judgment about what evidence should be found. End-to-end answer quality needs either expensive human evaluation or LLM-as-judge approaches with their own biases and failure modes.
Proper evaluation would measure several things: edge precision/recall against human-annotated sample pages, community coherence (do members actually discuss related topics?), retrieval recall on curated question sets with known relevant passages, and answer quality scoring against human-written reference answers. The infrastructure for this exists; the annotation effort is what’s missing.
In truth, this experiment started from a combination of a gut feeling raised from four years of hammering on vanilla-RAG-over-long-documents systems and unlocking access to claude code. As mentioned in the intro, code implementation is cheap now; exploring a system like this is much easier than it used to be. Despite not having strong evals, I think this exploration added useful techniques: edit-based memory, TTL/LRU bounds, topic graduation, deterministic linking, degeneration prevention and more.
I want to follow on from this post with both careful evaluation results (hopefully I’ll have some lessons around using Claude Code to create evals) as well as transforming LAD-RAG++ into something that could run at scale in production.
A Note About GraphRAG
There are some that are claiming vector search + GraphRAG is the future while others are saying vanilla vector search outperforms GraphRAG. In case the graph-based approach in LAD-RAG is setting off alarms in anyone’s head, I wanted to try and address some of these concerns here.
The linked paper makes important criticisms of GraphRAG approaches, but those criticisms target a fundamentally different architecture than LAD-RAG. Understanding the distinction matters if you’re evaluating whether LAD-RAG’s graph-based approach is worth the complexity.
What GraphRAG Does (and Why It Struggles)
The GraphRAG approaches evaluated in the paper share a common pattern: they extract knowledge graphs from text. An LLM processes documents and outputs entity-relation triplets like (Password Policy, REQUIRES, 12 characters). Retrieval then operates over these triplets, either directly or through community summaries built on top of them.
The paper identifies a critical flaw: extraction is lossy. Only ~65% of answer entities appeared in the constructed knowledge graphs. Converting rich document text into sparse triplets discards the detail needed for many questions. Community-based GraphRAG compounds this by summarizing communities, further abstracting away from source content. The paper found that RAG consistently outperformed GraphRAG on detail-oriented and single-hop questions precisely because RAG retrieves original text while GraphRAG retrieves extracted abstractions.
How LAD-RAG Differs
LAD-RAG’s graph is not a knowledge graph. The difference matters:
- Nodes ARE the original document elements. A paragraph node contains the full paragraph text. A table node contains the full table. Nothing is extracted or abstracted away. When you retrieve a node, you retrieve exactly what the document author wrote.
- Edges represent document structure and semantic flow.
IS_PART_OF_SECTIONcaptures hierarchy.CONTINUEScaptures narrative flow.REFERENCEScaptures cross-page connections. These edges organize content rather than replacing it. - The graph enables navigation. When
Contextualizeexpands from a found paragraph to its community, you get the surrounding paragraphs, the section header, the related tables all in their original form. The graph tells you what else is related; the nodes give you what it actually says.
This means LAD-RAG keeps the original text; the failure mode that paper describes (extraction losing 35% of answer entities) doesn’t apply. You get the detail-preservation of vanilla RAG with the structural awareness graphs provide.
The Hybrid Approach
LAD-RAG explicitly maintains both neural and symbolic retrieval. The paper found RAG and GraphRAG are “complementary, each excelling in different aspects”, RAG for detail-oriented queries, GraphRAG for multi-hop reasoning. LAD-RAG’s agent has access to both: semantic search over node embeddings (the RAG pathway) and graph traversal via Contextualize (the structural pathway). The agent chooses based on the question.
A Note About Multi-Document Processing and Inference
So far this blog has discussed LAD-RAG++ running over a single document. But many real-world systems require ingestion and inference over multiple documents. In Drata’s VRM product, for example, a vendor security review occurs over all of a vendor’s compliance documents. There is no inherent limitation in LAD-RAG++ that precludes it from running over multiple documents. In terms of what we’ve discussed here, small changes to for e.g. global node indexes and how tool calls present results to the LLM would need to change, but nothing that introduces a large amount of complexity.
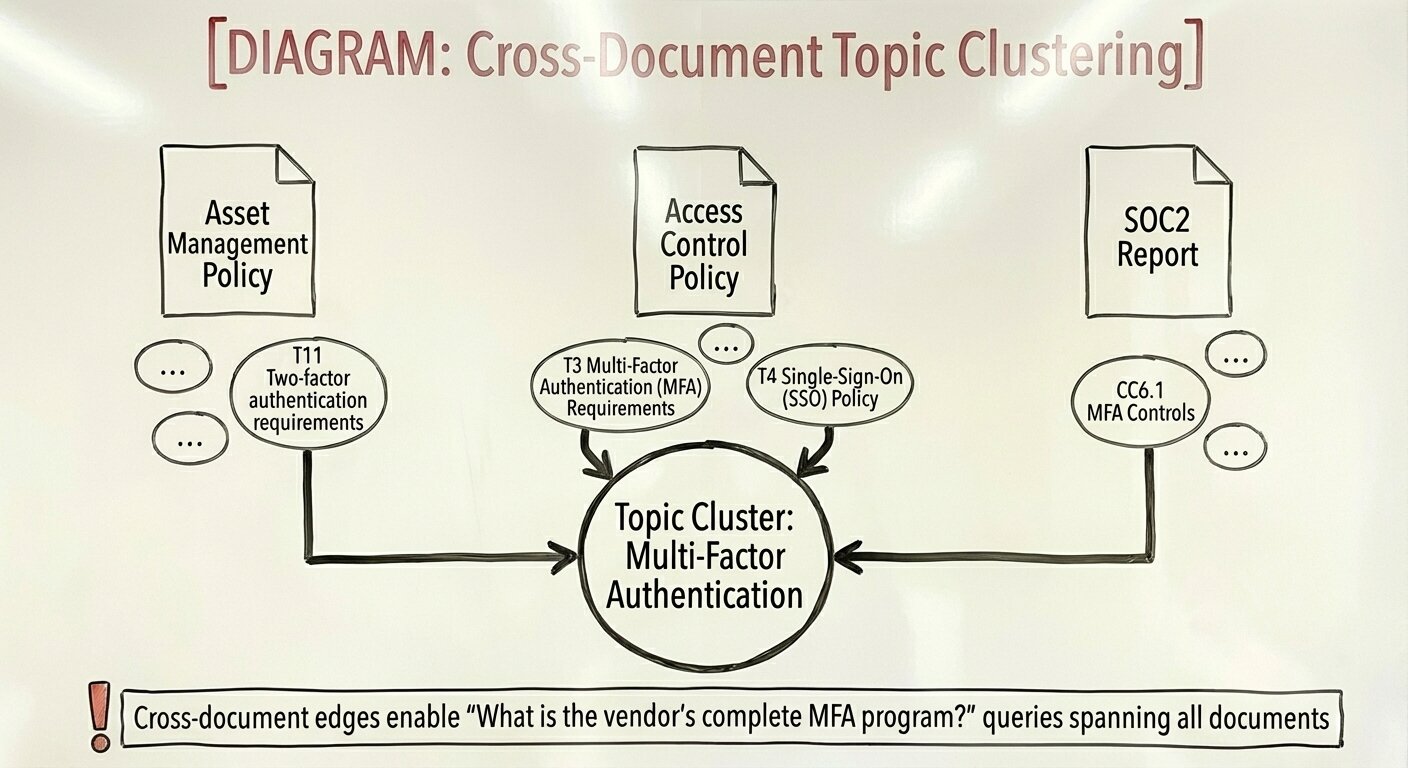
I wanted to briefly introduce something I realized as I was working on the document processing step. The entities and topics LAD-RAG extracts from documents in order to create cross-page connections could also be used to create cross document connections. Observe the topics below extracted from two different policy documents that address unique subjects:
<semantic_topics>
Asset Management
├─ T0 Asset Management Policy (3 nodes)
├─ T1 Asset Lifecycle Management (2 nodes)
├─ T2 Physical and Virtual Asset Management (3 nodes)
├─ T3 Asset Inventory Process (8 nodes)
├─ T4 Illegal and Unauthorized Software Identification (1 nodes)
├─ T5 Asset Listing Requirements (3 nodes)
├─ T6 Physical Asset Inventory Management (3 nodes)
├─ T7 Device Data Wipe Policy (1 nodes)
├─ T8 Virtual Asset Inventory Management (3 nodes)
├─ T9 System Retirement Standards (4 nodes)
└─ T10 System Hardening Standards (3 nodes) Authentication
└─ T11 Two-factor authentication requirements (1 nodes) Infrastructure Configuration and Maintenance
├─ T12 Workstation and Server Patching (1 nodes)
├─ T13 Internal Infrastructure Patching (1 nodes)
├─ T14 Infrastructure Documentation and Configuration Standards (1 nodes)
├─ T15 Endpoint Protection Deployment (1 nodes)
├─ T16 Mobile Device Management (MDM) Implementation (1 nodes)
└─ T17 Password Management System Deployment (1 nodes)
</semantic_topics>
<semantic_topics>
Access Control
├─ T0 User Identification Requirements (5 nodes)
├─ T1 Password Requirements (14 nodes)
├─ T2 Access Lifecycle Management (8 nodes)
├─ T3 Multi-Factor Authentication (MFA) Requirements (4 nodes)
├─ T4 Single-Sign-On (SSO) Policy (1 nodes)
├─ T5 Authenticator Security Requirements (4 nodes)
├─ T6 Session Security Requirements (3 nodes)
├─ T7 Principle of Least Privilege (2 nodes)
├─ T8 Access Request and Approval Process (4 nodes)
├─ T9 Role-Based Access Control (RBAC) (2 nodes)
├─ T10 User Access Awareness (1 nodes)
├─ T11 User Access Reviews (4 nodes)
├─ T12 Segregation of Duties (1 nodes)
├─ T13 Default Account Security (1 nodes)
├─ T14 Service Account Management (7 nodes)
├─ T15 Prohibited Account Types (1 nodes)
├─ T16 Policy Compliance and Enforcement (1 nodes)
└─ T17 Document Revision History (1 nodes)
</semantic_topics>
T11 in the first block and T3/T4 in the second block both address multi-factor authentication. When conducting a vendor security review, you likely want to connect “multi-factor authentication” across all documents added to the review to get a complete picture of the vendor’s MFA program. The LAD-RAG approach to constructing document graphs could be extended here where similar topics could be clustered across documents either during inference or before. During processing, discovered clusters could be analyzed by LLMs to create a complete picture of common themes across documents before inference even begins. I believe there are a lot of interesting features that could fall out of these extracted entities/topics etc.
Conclusion
LAD-RAG’s approach works. Layout-aware extraction, symbolic document graphs, and dynamic agentic retrieval address real failures in vanilla RAG systems. But making these ideas work on long, dense, real-world documents required significant engineering.
At Drata’s scale, stability matters as much as capability, our customers depend on consistent, reliable document processing. A system that works on a 10-page document may fail catastrophically on page 50 of a 300-page report. The techniques documented here, edit-based memory, TTL/LRU bounds, topic graduation, deterministic linking, degeneration prevention, aren’t optimizations. They’re requirements for production stability.
The experiment continues. Proper evaluation infrastructure, production deployment on ephemeral GPUs, and testing across diverse document types remain ahead. But the core question: can graph-structured document processing enable better retrieval than vanilla RAG? feels closer to being answered. For long, dense documents like the documents in the compliance field, the answer looks like yes. Cheers to the LAD-RAG authors for such an innovative approach.